

Durante décadas, la industria fue moviendo el equilibrio entre dos fuerzas: orden (coordinar trabajo, controlar calidad) y aprendizaje (descubrir qué hace falta de verdad, reaccionar a cambios). Cada metodología aparece para resolver un cuello de botella concreto, y al hacerlo introduce otro.
Si este artículo te tiene que servir como “referencia histórica” para comparar enfoques, quédate con esto: el cambio de metodología casi siempre es un intento de bajar el coste del retrabajo acercando el feedback a donde se toman las decisiones. Esa es, de fondo, la misma obsesión que atraviesa desde la ingeniería “plan-driven” hasta el manifiesto ágil: aprender antes para pagar menos después.
Tabla rápida: evolución, cuellos de botella y las cinco “cuentas”
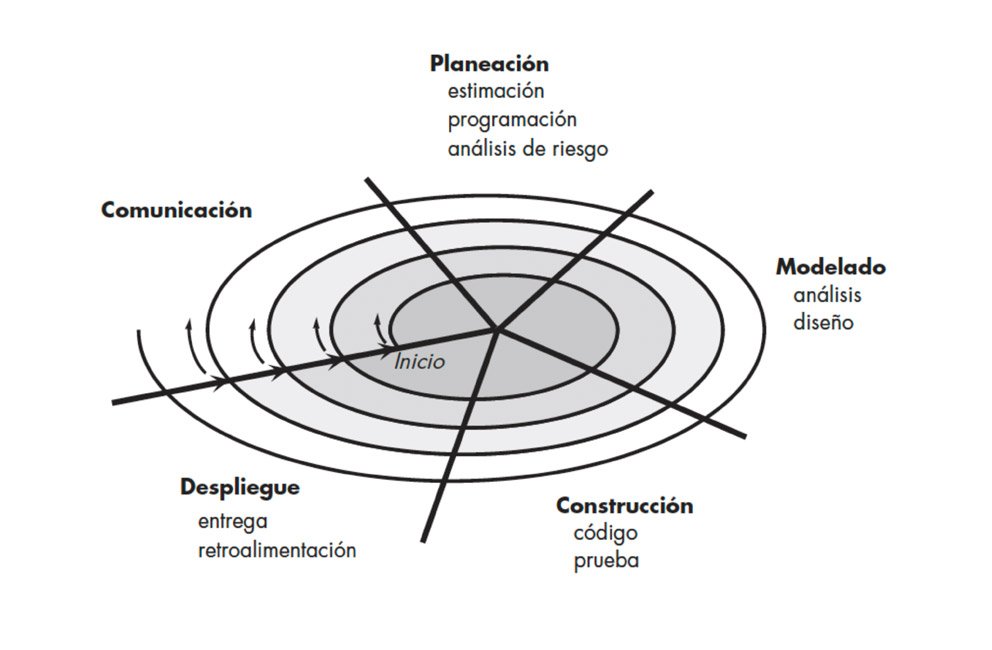
Usamos cinco “cuentas” para mapear el trabajo: comunicación, planeación, modelado, construcción y despliegue. Cuando una metodología cambia, normalmente cambia qué cuenta refuerza y dónde se atasca.
| Método/Proceso | Qué aportaba | Cuenta que reforzaba | Cuenta donde se atascaba | Motivo que empuja el cambio | KPIs de progreso (típicos, sobre todo negocio) |
|---|---|---|---|---|---|
| Ad-hoc / “a ojo” | Velocidad inicial, poca fricción | Comunicación (por proximidad) | Planeación y Modelado (implícitos) → Construcción caótica | La complejidad supera la cabeza del equipo | Horas consumidas, “% hecho”, tickets cerrados, demo informal (poca fiabilidad) |
| Cascada / V-Model | Orden, trazabilidad, verificación alineada | Comunicación y Planeación (definir y acordar) | Despliegue (feedback tardío) y Construcción (integración al final) | El aprendizaje real llega después del plan | Hitos por fase (sign-offs), trazabilidad, cobertura de requisitos; EVM (CPI/SPI, varianzas de coste/plazo) |
| Incremental | Valor temprano sin big bang, integración progresiva | Despliegue (entregar antes) y Construcción (integrar antes) | Planeación (priorizar) y Modelado (cohesión entre incrementos) | Time-to-value + reducir riesgo de integración tardía | Incrementos entregados, burnup/burndown de release, estabilidad de integración, defectos por incremento |
| Prototipos | Aprender rápido qué hay que construir | Comunicación (alinear expectativas) | Modelado (si el prototipo se “queda”) y Construcción (base frágil) | Requisitos confusos: necesitamos ver para entender | Validación de hipótesis: éxito en tareas, errores, tiempo por tarea, feedback cualitativo; decisión de “aprobado/descartado” |
| Espiral | Riesgo como motor del ciclo | Planeación (decidir por riesgo) y Modelado (mitigar) | Planeación (disciplina) y Comunicación (evaluación continua) | Incertidumbre/criticidad hacen inviable una sola jugada | Riesgos cerrados (risk burndown), exposición al riesgo, hitos LCO/LCA/IOC (anchor points) |
| Agile (Scrum/XP…) | Feedback continuo, adaptación, entrega frecuente | Comunicación y Despliegue (ciclos cortos) | Modelado (contratos) y Despliegue (pipeline/entornos) con silos | Cambio constante + aprender en ciclos cortos | Sprint goals cumplidos, burnup/burndown, velocidad (tendencia); métricas de flujo (lead/cycle time, throughput) y DORA (lead time, despliegues, fallos, recuperación) |
La curva del coste del cambio: por qué el feedback manda
Hay una idea que atraviesa toda esta historia: cambiar algo tarde suele costar mucho más que cambiarlo pronto. Esto se popularizó con la “cost of change curve” asociada a Barry Boehm, que la recoge en Software Engineering Economics (1981): cuanto más avanzado está el ciclo, más artefactos dependen de la decisión (código, pruebas, documentación, datos, despliegues, usuarios), y más caro es moverla.
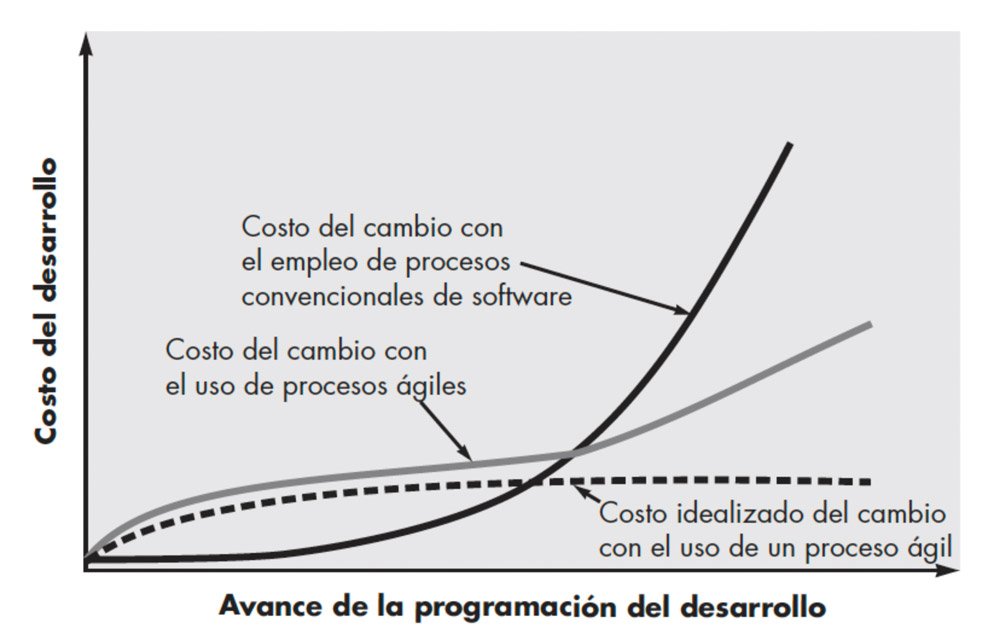
No es una ley física con multiplicadores universales. De hecho, trabajos posteriores en entornos de alta criticidad muestran el mismo patrón general, pero con pendientes distintas según contexto y disciplina: por ejemplo, Stecklein et al. (NASA), en Error Cost Escalation Through the Project Life Cycle (2004), analizan cómo escala el coste de arreglar errores cuando se descubren tarde. Depende de arquitectura, automatización, entorno regulatorio y madurez del equipo. Pero como mapa mental funciona: si el feedback llega tarde, el cambio llega caro, y eso empuja a buscar ciclos más cortos.
El elefante en la sala: el retrabajo (casi siempre aparece)
Esto no es una anécdota: los estudios clásicos de “por qué fallan los proyectos” llevan décadas señalando causas repetidas (requisitos incompletos, cambios constantes, baja implicación de usuario). El nombre cambia según la fuente; el patrón, no.
En la mayoría de proyectos, el final real no coincide con el plan. Llegas a una demo, a un cierre de sprint o a una fecha de entrega y descubres una combinación conocida: requisitos incompletos, producto mal entendido, integración ignorada o validaciones que nadie hizo hasta el último momento.
El síntoma es reconocible: un proyecto “de 8 meses” se alarga 3 más, o se sale a producción sin todo lo prometido dejando una “fase 2” que en realidad es deuda de entrega. Informes tipo CHAOS (Standish Group) llevan años describiendo ese mundo de proyectos “challenged”: tarde, sobre presupuesto o con alcance recortado. En consultoría esto tiene traducción directa: más retrabajo significa más horas no previstas y, por tanto, menos margen.
Con este marco, la evolución de metodologías se entiende mejor: cada etapa intenta mover verificación y aprendizaje hacia antes para que el retrabajo no explote al final. En benchmarks industriales se citan rangos grandes, pero persistentes, de rework asociado a requisitos cambiantes o mal entendidos: por ejemplo, presentaciones de benchmarking de ISBSG recogen cifras del orden de “30–60% de rework” en desarrollo atribuible a requisitos mal entendidos o cambiantes. Si no mueves el feedback, acabas pagándolo en horas al final.
El mapa mental: las cinco “cuentas” que todas las metodologías acaban pagando
Da igual la etiqueta del proceso: el trabajo siempre termina cayendo en cinco bloques. Si no los nombras, no desaparecen; se vuelven implícitos. Este marco se apoya en una formulación clásica muy extendida (Pressman como referencia base), pero aquí lo usamos como herramienta de lectura, no como autoridad.
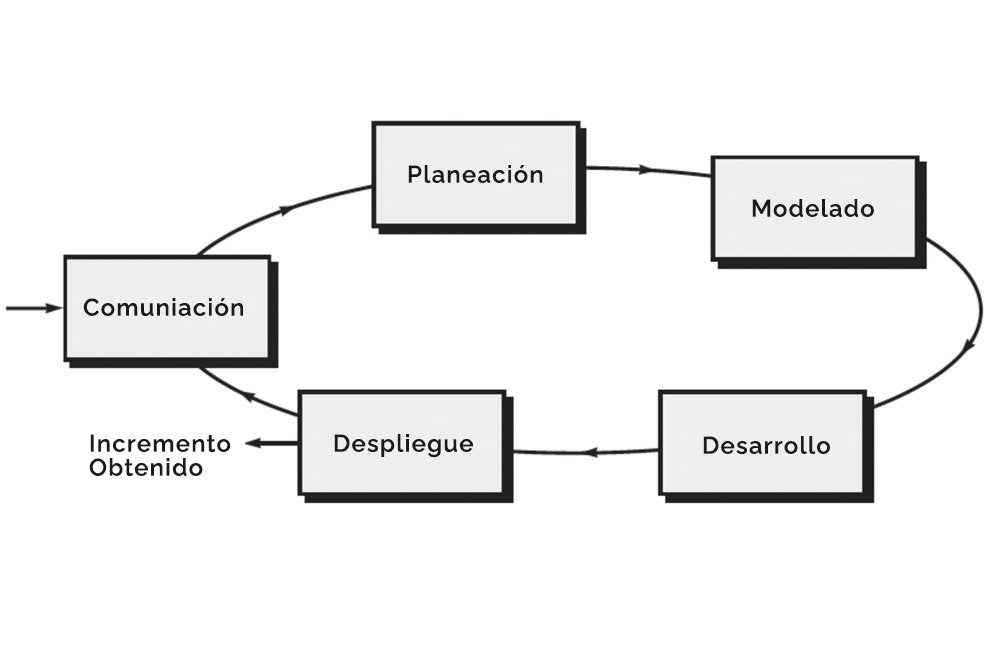
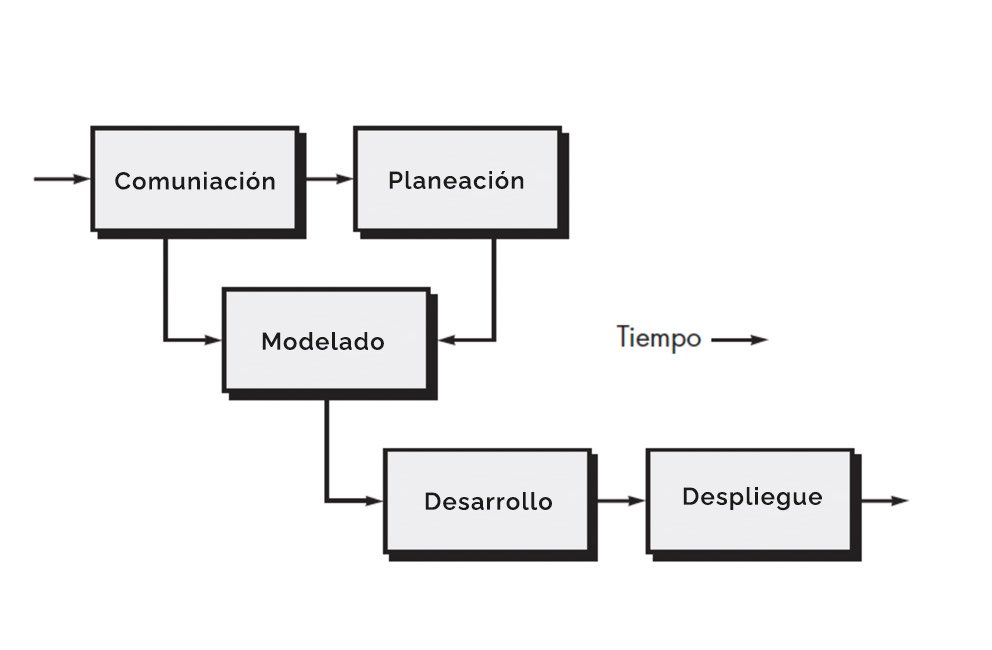
Comunicación
Aquí decidimos qué problema resolvemos, qué significa “éxito” y qué no vamos a hacer. En proyectos suele arrancar en preventa: comerciales acotan (o prometen) alcance y plazos; analistas y negocio aterrizan necesidades; y en producto continuo esto vive en Product (PM/PO) y en los stakeholders que van a sufrir el resultado.
Cuando esta cuenta está floja, el resto se convierte en ruido: planeamos sobre arena, modelamos sobre suposiciones y construimos cosas “correctas” para un problema equivocado.
Planeación
Aquí convertimos lo anterior en compromisos operativos: qué entra primero, qué depende de qué, cuánto riesgo aceptamos y qué señal nos dirá que vamos bien. Lo puede liderar gestión de proyecto/delivery, un Scrum Master con rol real, o repartirse entre PO y equipo.
Cuando falla, no falla “la estimación”: falla la conversación sobre límites. Y cuando los límites no están, el retrabajo encuentra sitio.
Modelado
Aquí decidimos si el trabajo puede paralelizarse sin romperse: arquitectura, dominio, datos, interfaces y contratos. En equipos pequeños lo llevan seniors y tech leads; en entornos grandes aparecen arquitectos y funciones transversales como seguridad, privacidad o plataforma.
Modelado no es dibujar cajas: es fijar acuerdos para que construcción no sea una negociación constante. Si no hay contratos (APIs, eventos, esquemas, versionado), la integración se vuelve un acto de fe.
Construcción
Aquí implementamos, integramos y probamos. No es solo “escribir código”: es hacer que el sistema funcione como un todo. Entra backend, frontend, mobile, QA/testing (si existe de verdad) y también plataforma/SRE cuando afecta a pipelines y entornos.
Los cuellos de botella típicos son humanos: revisiones que no escalan, integración que rompe por cambios no coordinados y pruebas que llegan tarde o son decorativas.
Despliegue
Aquí el software demuestra si está vivo: release, operación, soporte, incidentes, rollback y compatibilidad. Suelen vivir DevOps/Platform/SRE, operaciones y soporte; y en producto serio, también negocio, porque desplegar implica adopción y a veces migraciones.
Si despliegue está roto, lo demás se vuelve ficción: sin camino de entrega funcional y observabilidad mínima, no hay feedback fiable ni capacidad de sostener el sistema.
Línea temporal: qué resolvía cada etapa y qué empezó a romperse
El coste de cambiar tarde: la curva de Boehm (y por qué empuja la evolución)
Cuando hablamos de “cambio”, no hablamos de un capricho del cliente: hablamos de cuánto cuesta corregir un error de entendimiento cuando ya hemos pagado diseño, construcción, pruebas y despliegue.
Barry W. Boehm lo convirtió en una idea muy operativa: la corrección se encarece conforme avanzamos en el ciclo. No es magia: a medida que el software se integra, hay más dependencias, más validación que repetir y más impacto colateral. Un informe de NASA (Stecklein et al.) lo resume con datos y referencias, citando a Boehm: encontrar y corregir después de la entrega puede ser del orden de decenas o incluso ~100× más caro que hacerlo en requisitos y diseño temprano.
Esta “curva” no te obliga a ser ágil ni a ser prescriptivo. Te obliga a reconocer una realidad: si el feedback llega tarde, pagas.
El re-trabajo (el coste que casi nadie planifica)
En la práctica, el re-trabajo no es un accidente: es una parte estructural del coste. Barry Boehm y Victor Basili lo describieron como “avoidable rework” y lo trataron como una palanca mayor de productividad. Y hay evidencia industrial de que puede consumir una porción enorme del esfuerzo: Lars-Ola Damm, estudiando proyectos industriales, habla de rangos del 20–80% dependiendo de madurez y complejidad.
La escena es conocida: al final de un proyecto, un sprint o una demo, descubrimos que no se cumplen todos los requisitos o que el producto no se ha entendido bien. Si el plan era de ocho meses, se alarga; si hay fecha de producción, se recorta alcance o se pospone calidad. Y si estamos en consultoría, ese retraso y ese retrabajo se traducen en más coste y menor margen.
Evolución de metodologías
Ad-hoc: cuando el equipo cabe en una sala
Qué aportaba. Velocidad y autonomía. La comunicación “por osmosis” funciona cuando todos comparten contexto y el sistema es pequeño.
Dónde se atasca. En cuanto crece el producto, el cuello se mueve a comunicación y planeación: decisiones no registradas, prioridades confusas y retrabajo. La calidad aparece tarde porque verificación y despliegue no están integrados.
KPIs de progreso (en la práctica). En ad-hoc rara vez hay KPIs “serios”: el progreso se cuenta por horas consumidas, por sensación de avance, por número de tickets cerrados o por “ya funciona en mi máquina”. A negocio le da tranquilidad una demo informal, pero el indicador suele ser poco fiable porque no captura integración, calidad ni camino real a despliegue.
Documentación y código en la práctica. La documentación suele ser conversación, tickets sueltos y algún README. Mientras el sistema es pequeño, ese pacto implícito funciona. Cuando crece, lo escrito envejece rápido y lo no escrito se convierte en malentendido. El código queda como única fuente de verdad, pero una fuente difícil de interpretar para negocio.
Fuente de la verdad: teoría vs práctica. En teoría, la verdad es el contexto compartido del equipo. En la práctica, cuando el contexto deja de ser común, la verdad se fragmenta: cada persona recuerda una versión distinta, y el código termina actuando como árbitro… tarde, cuando ya hay fricción y retrabajo.
Cascada y V-Model: el plan como mecanismo de control
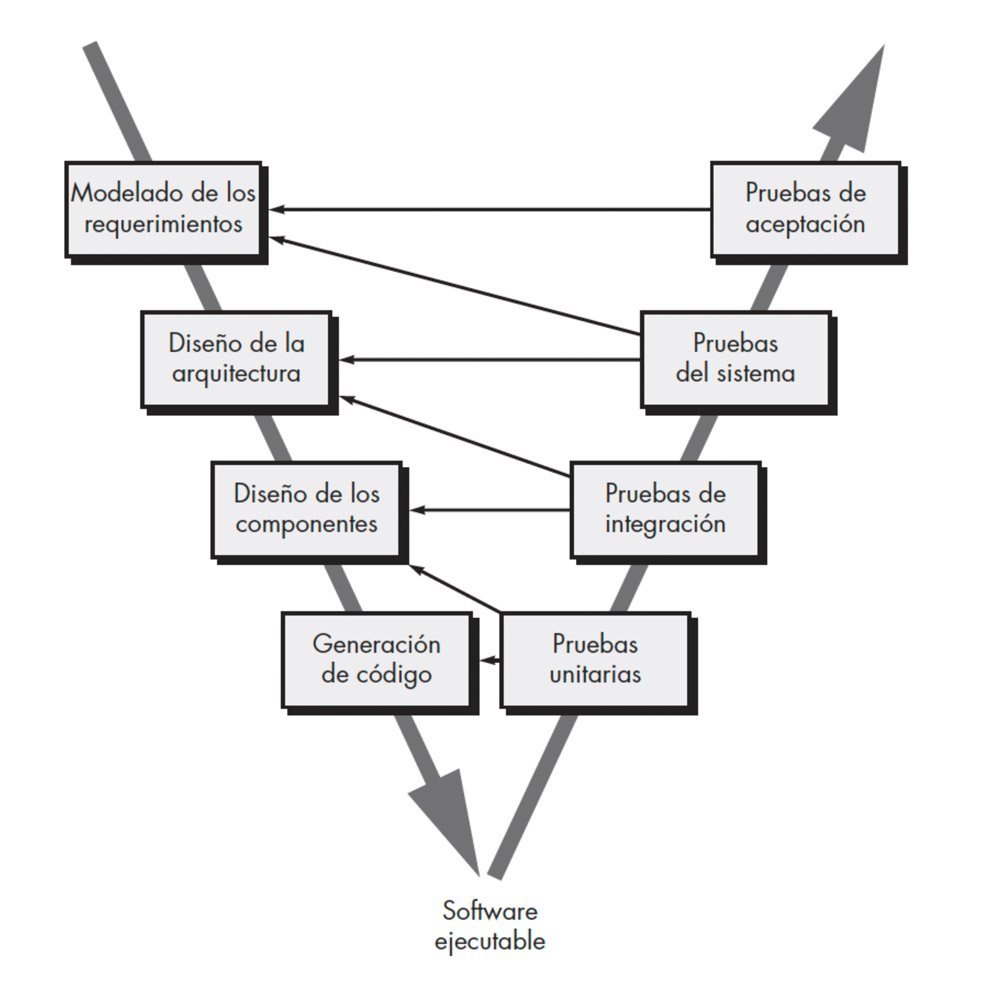
Qué aportaba. Orden y trazabilidad, reforzando comunicación y planeación. El V-Model conecta decisiones tempranas con verificación posterior: lo que defines arriba, lo validas abajo.
Dónde se atasca. El cuello real es el feedback: la verdad del producto se descubre tarde (integración, UAT, primer despliegue). Si el aprendizaje llega después de pagar diseño y construcción, el cambio es carísimo.
KPIs de progreso (en teoría y en entornos serios). Aquí el progreso se mide por hitos y “phase gates”: documentos aprobados, requisitos trazados, diseño revisado, y pruebas planificadas y ejecutadas. En entornos de adquisición y proyectos grandes, esto suele apoyarse en Earned Value Management para cuantificar avance frente a plan (EV/PV/AC y sus índices CPI/SPI), como recoge la guía DoD EVMSIG (2019).
En sistemas de alta criticidad, el V-Model se apoya además en revisiones técnicas formales (SRR, PDR, CDR, TRR…), donde “progreso” significa cumplir criterios de entrada/salida, no solo haber gastado presupuesto, como formaliza la normativa de ingeniería de sistemas de NASA (NPR 7123.1).
Documentación y código en la práctica. La documentación se trata como contrato: especificaciones, diseño, trazabilidad y planes de prueba. En teoría, el código implementa lo documentado. En la práctica, o la documentación pesa tanto que ralentiza feedback, o el proyecto cambia y el documento se queda atrás. El contrato se rompe: el documento dice una cosa, el código hace otra, y el coste se paga en excepciones, parches y discusiones.
Un apunte histórico útil: el “waterfall” que se popularizó como secuencia rígida no refleja bien las advertencias originales. Winston W. Royce, en su paper de 1970 (Managing the Development of Large Software Systems), ya señalaba que ejecutar el flujo de forma puramente secuencial era arriesgado e introducía la necesidad de realimentación y validación temprana.
Fuente de la verdad: teoría vs práctica. En teoría, la fuente de verdad es el conjunto de documentos y su trazabilidad (requisitos → diseño → pruebas). En la práctica, cuando aparecen cambios, la verdad se desplaza a la gestión del cambio y a lo que realmente se prueba y despliega. Si no hay disciplina para mantener documentos alineados, el código y el comportamiento observado acaban mandando.
Incremental: entregar antes para enterarse antes
Qué aporta. Valor temprano sin big bang. Refuerza despliegue (entregar antes) y construcción (integrar antes), reduciendo el riesgo de integración tardía.
Dónde se atasca. El cuello se mueve a planeación y modelado: priorización y cohesión entre incrementos. Sin una línea arquitectónica mínima, la deuda explota en el tercer o cuarto incremento.
Documentación y código en la práctica. Suele documentarse “lo justo” por incremento: alcance, decisiones relevantes y contratos de integración. Si solo documentamos features, el sistema pierde cohesión; si documentamos demasiado, volvemos a pagar el coste de un plan que el próximo incremento puede invalidar.
Fuente de la verdad: teoría vs práctica. En teoría, la verdad es el incremento entregado más sus contratos y decisiones: cada entrega cristaliza qué es real. En la práctica, muchos equipos acaban haciendo “mini-cascadas” por incremento: documentos por delante, integración al final del ciclo, y la verdad reaparece tarde. Cuando eso pasa, el incremental pierde su ventaja principal: enterarse antes.
Prototipos: aprender antes de comprometerse
Qué aporta. Un artefacto para desbloquear comunicación cuando el problema no está bien formulado. La gente descubre requisitos al ver algo.
Dónde se atasca. El riesgo está en la frontera entre aprender y construir: si el prototipo se convierte en producto sin disciplina, modelado y construcción quedan apoyados en una base frágil y el retrabajo se dispara.
Documentación y código en la práctica. El prototipo suele ser el documento principal. Lo que merece quedar escrito son aprendizajes: qué se descartó, qué se confirmó, qué decisión se tomó y por qué. El antipatrón es fingir precisión o convertir el prototipo en producción sin contratos. Hay literatura industrial que lo formula de forma muy directa: en un estudio sobre prototipado rápido, Gordon y Bieman advierten que un prototipo construido deprisa, “masajeado” hasta convertirse en producto y documentado a posteriori puede resultar muy difícil de mantener y evolucionar. Y Atwood y colegas, en Prototyping Considered Dangerous (INTERACT ’95), añaden otra capa:
Fuente de la verdad: teoría vs práctica. En teoría, la verdad vive en lo aprendido (decisiones y descartes), y el prototipo es una herramienta temporal. En la práctica, es frecuente que el prototipo “se quede” por presión de entrega: entonces el código del prototipo se convierte en verdad operativa, pero sin haber sido diseñado para soportarla. Es una receta clásica de retrabajo.
Espiral: el riesgo decide el ciclo
Qué aporta. Riesgo explícito como motor: cada vuelta combina planificación, análisis de riesgos, ingeniería y evaluación, ajustando coste y plan.
Dónde se atasca. Requiere disciplina real para identificar riesgos, mitigar y demostrar reducción. Si no hay músculo para sostenerlo, se degrada a “iterar mucho” sin control.
Documentación y código en la práctica. No se documenta por amor al documento: se documenta para gestionar riesgo. Lo que suele sobrevivir son decisiones, supuestos, mitigaciones y evidencias. El coste es el mismo: si no se revisa y mantiene, pierde su función y el riesgo vuelve a esconderse.
Fuente de la verdad: teoría vs práctica. En teoría, la verdad está en el análisis de riesgos y en la evidencia de que se han mitigado (no solo en el código). En la práctica, si la organización no se cree ese trabajo o no sabe sostenerlo, la verdad vuelve a desplazarse al software “que funciona hoy” y a la intuición del equipo, y se pierde la trazabilidad del porqué.
Agile: el presente… y sus trampas
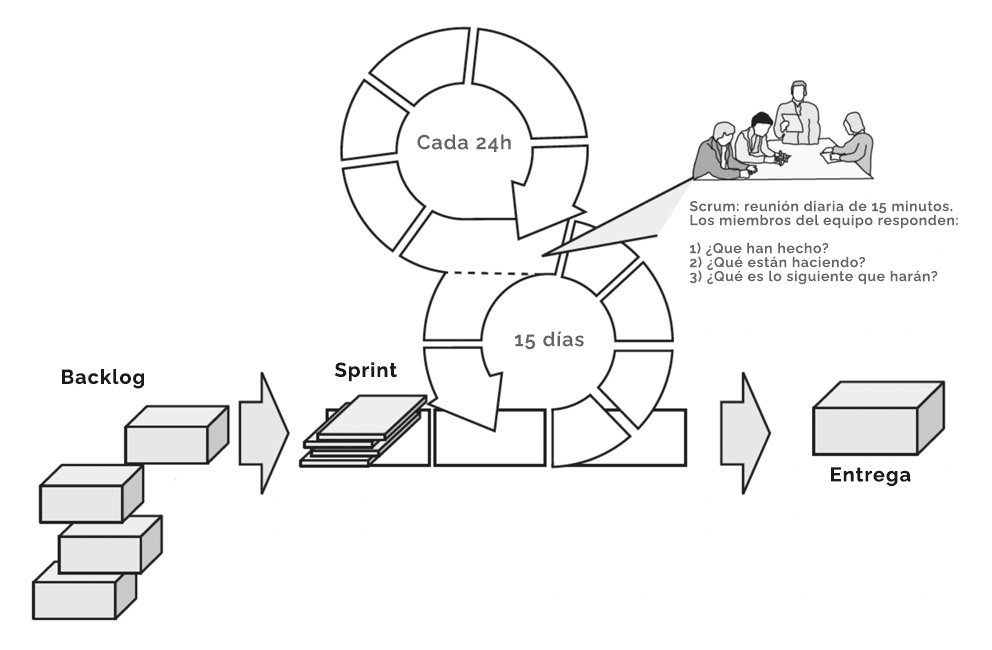
Qué aporta. Ciclos cortos de feedback, colaboración y adaptación. El Manifiesto Ágil (2001) lo dice sin rodeos al priorizar working software por encima de documentación exhaustiva y la respuesta al cambio por encima de seguir un plan. La idea es reducir el lote de cambio y aprender antes.
Dónde se atasca. En la práctica, raramente se ejecuta “de libro”. Muchas organizaciones se quedan en el agile de roles y ceremonias: nombramos PO, hacemos dailies y sprints, y concluimos que ya somos ágiles. El cuello real suele ser alineamiento y dependencias.
Cuando trabajamos en silos (DevOps, backend, frontend), la cadena se rompe por el eslabón más lento: si DevOps no prepara entornos, backend no despliega; si backend no despliega, frontend improvisa para probar. Si además no hay contratos, la alineación backend–frontend se convierte en un ejercicio de fe.
Documentación y código en la práctica. La documentación suele caer al último escalón de prioridad. Si se escribe, muchas veces es porque el cliente exige visibilidad; rara vez tiene alta precisión y queda obsoleta cuando el proyecto aprende algo y decide cambiar. Se abre una brecha: el cliente cree que el documento fija alcance, el equipo cree que el backlog y el código reflejan la realidad. Sin contratos y criterios de aceptación verificables, esa brecha se paga en integración y negociación.
Fuente de la verdad: teoría vs práctica. En teoría, la verdad es el incremento “Done” (software funcionando) y los artefactos que hacen transparente el trabajo (backlog, objetivos, definición de hecho). La Scrum Guide (2020) es bastante explícita: la Definition of Done crea transparencia y, si no se cumple, el trabajo ni siquiera debería presentarse como incremento válido. En la práctica, aparece el “Scrum mecánico. En Scrum.org lo llaman directamente Zombie Scrum: algo que “parece Scrum desde lejos” pero no produce incrementos útiles ni aprendizaje real. La verdad termina repartida entre Jira, la realidad del pipeline, lo que hay desplegado y los acuerdos verbales.
Cierre: lo que de verdad cambia entre metodologías
La historia no va de “fases” ni de nombres. Va de dónde colocamos el control y cuándo buscamos verdad. Cuando el feedback llega tarde, el retrabajo se acumula; y cuando el retrabajo se acumula, la industria empuja hacia procesos que traen verificación y aprendizaje más cerca del día a día.
Nota sobre documentación en Agile
Si alguien necesita una “frase de referencia” para entender por qué, en muchos equipos ágiles, la documentación cae al último escalón, es esta: el Manifesto for Agile Software Development (2001) puso por delante el software funcionando frente a la documentación exhaustiva. La lectura sensata es equilibrio: documentar lo que reduce incertidumbre y retrabajo, pero no convertir la documentación en un fin en sí mismo.